데이터 중복 제거 작동 방식
Arcserve UDP 중복 제거 프로세스는 데이터를 여러 개의 데이터 블록으로 분할하며 각 블록마다 "해시"라는 고유한 식별자가 할당됩니다. 해시는 볼륨 클러스터를 기반으로 계산됩니다. 기본 중복 제거 블록 크기는 4KB(기본 볼륨 클러스터 크기가 대부분의 노드에서 4KB)입니다. 해시 값이 기존 백업 데이터의 해시 값과 비교되며, 중복 제거 참조가 발견되면 해당 데이터 블록은 백업되지 않습니다. 고유한 참조가 있는 데이터 블록만 백업됩니다.
다음 다이어그램은 Arcserve UDP에서 중복 제거가 작동하는 방식을 나타냅니다.
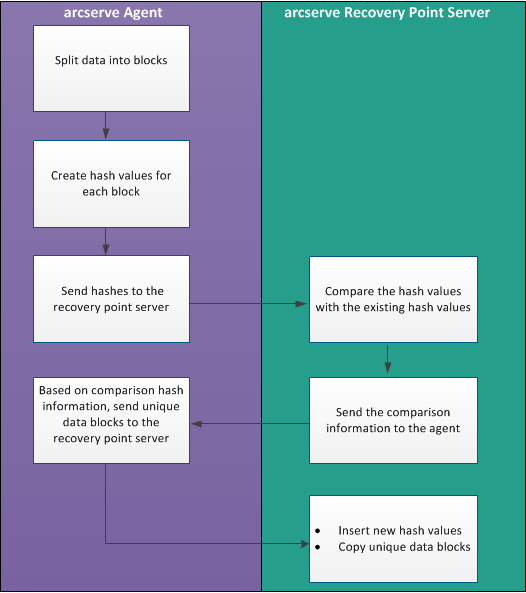
백업이 트리거되면 에이전트의 중복 제거 프로세스가 먼저 데이터를 여러 블록으로 분할하고 각 블록마다 고유한 해시 키 또는 값을 할당합니다. 그런 다음 해시 값이 복구 지점 서버로 전송됩니다. 복구 지점 서버에서 이러한 해시 값이 기존 해시 값과 비교되고 중복되는 해시 값이 필터링으로 제외됩니다. 그런 다음 비교 결과가 다시 에이전트로 전송됩니다. 이러한 중복 해시 정보에 기반하여 에이전트는 고유한 데이터 블록을 백업을 위한 복구 지점 서버로 전송합니다. 이러한 데이터 블록의 새로운 해시 값도 복구 지점 서버의 기존 해시 목록에 삽입됩니다.
에이전트가 여러 개인 경우 중복 제거 프로세스는 동일하게 유지되지만 여러 에이전트에서 중복되는 데이터는 필터링으로 제외됩니다. 따라서 여러 에이전트에서도 데이터 중복이 제거됩니다.
Arcserve UDP에서 데이터 중복 제거를 사용하여 얻는 이점은 다음과 같습니다.
- 더 신속한 전체 백업
- 더 신속한 병합 작업
- 전역 중복 제거 지원
- 최적화된 복제