

Note:To process two or more streams of backup data using multistreaming, you must license the Arcserve Backup Enterprise Module.
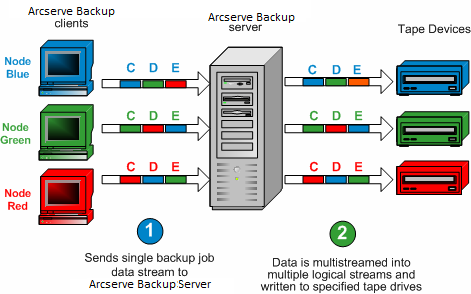
多数据流过程是:将备份作业分成多个同时运行的子作业(数据流),然后将数据发送到目标介质(磁带设备或文件系统设备)。在备份和恢复操作过程中,多数据流被用于最大限度地有效利用客户端计算机。执行较大的备份作业时多数据流非常有用,因为它能在多个备份设备间更加有效地划分多个作业。
通过多数据流,可以将备份作业拆分为使用所有可用磁带设备的多个作业,从而能够使用所有可用磁带设备。因此,与顺序方法相比,它将提高总体备份吞吐量。
您可以使用所有设备,也可以指定单个设备组。如果安装了 Arcserve Backup 产品磁带存储库选件,并且选择了存储库中的设备组,则多数据流将使用所有存储库设备。如果没有安装 Arcserve Backup 产品磁带存储库选件,则可以将设备放到不同的组中。对于转换器,创建的数据流(子作业)总数取决于磁带设备数。对于单个磁带驱动器设备,数据流总数取决于设备组的数量。
对于常规文件,在卷级执行多数据流(两个卷可以同时运行在两个不同的设备上);对于本地数据库服务器,在数据库级执行多数据流。对于首选共享文件夹、远程数据库服务器和 Windows 客户端代理,在节点级执行多数据流。
同时执行的作业数量只能与系统上的设备或组的数量相同。通过多数据流功能,将创建一个父作业,它将为您触发与卷数同样多的子作业。在一个设备上完成作业后,将执行另一个作业,直到没有作业可以执行。
多数据流的一些特征和要求如下:
JOB[ID][服务器名](多数据流子作业 [SID])[状态][开始时间 - 结束时间][作业号]
Note:SID Represents the sub job (child) ID.
请注意以下问题:
|
Copyright © 2016
|
|