

Arcserve UDP deduplication process splits data into data blocks and each block is assigned a unique identifier called hash. Hash is calculated based on the volume cluster. The default deduplication block size is 4KB (the default volume cluster size is 4KB for most of the nodes). These hash values are compared with the hash values of the existing backup data and if duplicate references are found, those data blocks are not backed up. Only data blocks with unique references are backed up.
The following diagram illustrates how deduplication works in Arcserve UDP.
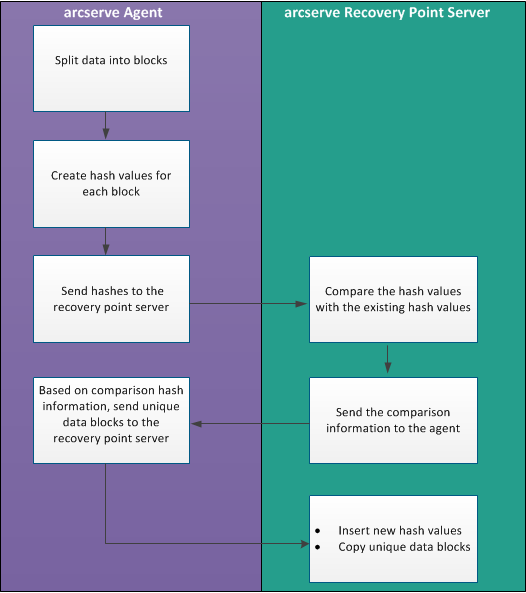
When a backup is triggered, the deduplication process on the agent first splits data into blocks and assigns a unique hash key or value to each block. The hash values are then sent to the recovery point server. At the recovery point server, these hash values are compared with the existing hash values and the duplicate hashes are filtered out. The comparison results are then sent back to the agent. Based on this duplicate hash information, the agent sends the unique data blocks to the recovery point server for backup. The new hash values of these data blocks are also inserted to its existing hash list on the recovery point server.
When there are multiple agents, the deduplication process remains the same, however, duplicate data from multiple agents are filtered out. This eliminates any duplication of data even from multiple agents.
The following are the benefits of using a Data Deduplication in Arcserve UDP
|
Copyright © 2015
|
|