

Arcserve UDP デデュプリケーション処理では、データはデータ ブロックに分割されます。各ブロックには、ハッシュと呼ばれる一意の識別子が割り当てられます。 ハッシュはボリューム クラスタに基づいて計算されます。 デフォルトのデデュプリケーション ブロック サイズは、4 KB です(デフォルトのボリューム クラスタ サイズは大半のノードで 4 KB です)。 これらのハッシュ値は既存のバックアップ データのハッシュ値と比較されます。重複した参照が見つかった場合、これらのデータ ブロックはバックアップされません。 一意の参照を持ったデータ ブロックのみがバックアップされます。
以下の図に、Arcserve UDP でデデュプリケーションがどのように動作するかを示します。
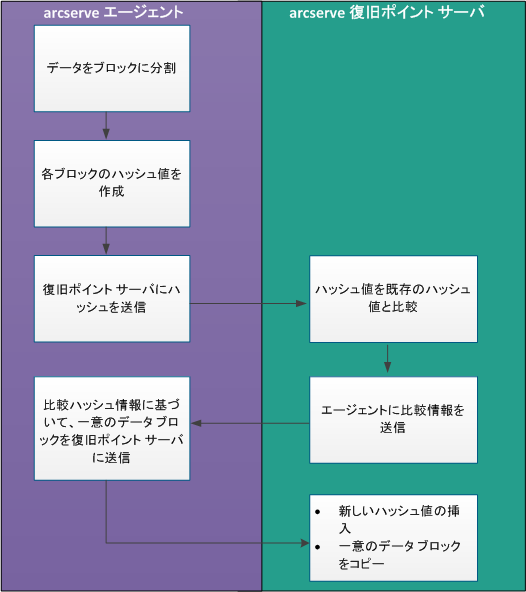
バックアップがトリガされると、エージェント上のデデュプリケーション プロセスはまずデータをブロックに分割し、一意のハッシュ キーまたは値を各ブロックへ割り当てます。 ハッシュ値は次に、復旧ポイント サーバに送信されます。 復旧ポイント サーバでは、これらのハッシュ値が既存のハッシュ値と比較され、重複したハッシュはフィルタされます。 次に、比較結果はエージェントに送信して戻されます。 この重複したハッシュの情報に基づいて、エージェントはバックアップ対象の一意のデータ ブロックを復旧ポイント サーバに送信します。 これらのデータ ブロックの新しいハッシュ値も、復旧ポイント サーバ上の既存のハッシュ リストに挿入されます。
複数のエージェントがある場合でも、デデュプリケーション処理は同様です。ただし、複数のエージェントからの重複データはフィルタされます。 これにより、複数のエージェントからのデータの重複も除去できます。
Arcserve UDP でデータ デデュプリケーションを使用する利点を以下に示します。
|
Copyright © 2015 Arcserve.
All rights reserved.
|
|