

Der Arcserve UDP-Deduplizierungsprozess unterteilt Daten in Datenblöcke. Jeder Block enthält eine eindeutige Kennung, die als Hash bezeichnet wird. Der Hash-Wert wird basierend auf dem Volume-Cluster berechnet. Die standardmäßige Größe von Deduplizierungsblöcken beträgt 4 KB (die standardmäßige Größe von Volume-Clustern beträgt auf den meisten Knoten 4 KB). Diese Hash-Werte werden mit den Hash-Werten der vorhandenen Sicherungsdaten verglichen. Wenn doppelte Verweise gefunden werden, werden die entsprechenden Datenblöcke nicht gesichert. Es werden nur Datenblöcke mit eindeutigen Verweisen gesichert.
Das folgende Diagramm veranschaulicht die Funktionsweise der Deduplizierung in Arcserve UDP.
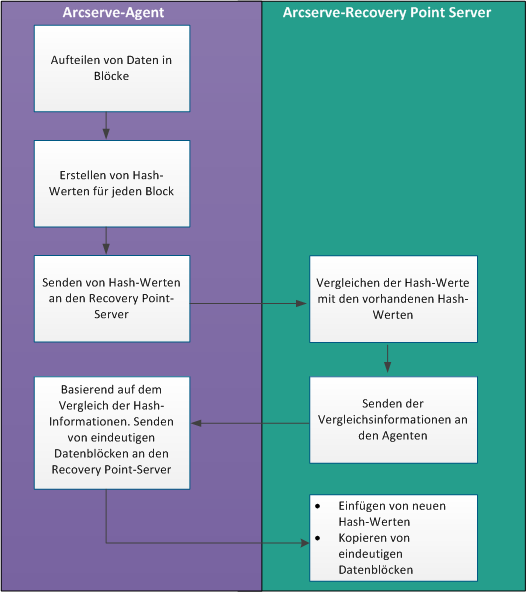
Wenn eine Sicherung ausgelöst wird, unterteilt der Deduplizierungsprozess auf dem Agent die Daten zunächst in Blöcke und weist jedem Block einen eindeutigen Hash-Schlüssel bzw. Hash-Wert zu. Anschließend werden die Hash-Werte an den Recovery Point Server gesendet. Auf dem Recovery Point Server werden diese Hash-Werte mit den vorhandenen Hash-Werten verglichen, und duplizierte Hash-Werte werden herausgefiltert. Die Ergebnisse dieses Vergleichs werden an den Agent zurückgesendet. Auf der Grundlage dieser Information zu duplizierten Hash-Werten sendet der Agent die eindeutigen Datenblöcke an den Recovery Point Server, um sie zu sichern. Die neuen Hash-Werte für diese Datenblöcke werden auch in die Liste der vorhandenen Hash-Werte auf dem Recovery Point Server aufgenommen.
Wenn mehrere Agents verwendet werden, ist der Deduplizierungsprozess derselbe, allerdings werden duplizierte Daten für mehrere Agents herausgefiltert. Dadurch werden auch duplizierte Daten von verschiedenen Agents vermieden.
Der Einsatz von Datendeduplizierung in Arcserve UDP bietet folgende Vorteile:
|
Copyright © 2015 Arcserve.
Alle Rechte vorbehalten.
|
|