

Le processus de déduplication de Arcserve UDP fractionne les données en blocs de données, auxquels est affecté un identificateur unique appelé hachage. Le hachage est calculé selon le cluster de volume. La taille de bloc de déduplication par défaut est 4 Ko (la taille de cluster de volume par défaut est 4 Ko pour la plupart des noeuds). Ces valeurs de hachage sont comparées avec les valeurs de hachage des données de sauvegarde existantes et si des références dupliquées sont identifiées, les blocs de données correspondants ne sont pas sauvegardés. Seuls les blocs de données avec des références uniques sont sauvegardés.
Le diagramme suivant illustre le fonctionnement de la déduplication dans Arcserve UDP.
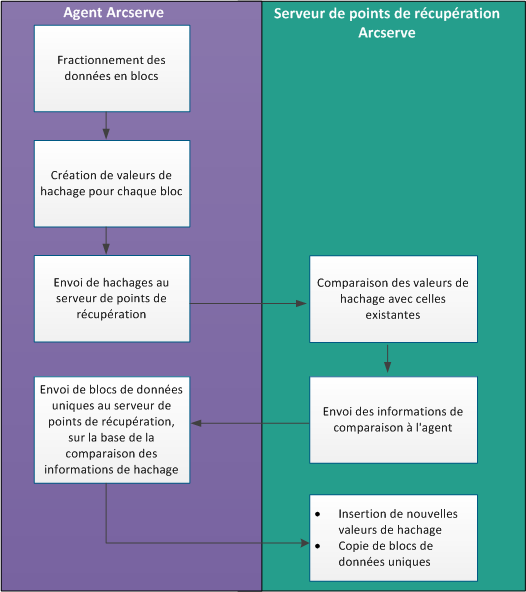
Lorsqu'une sauvegarde est déclenchée, le processus de déduplication sur l'agent fractionne d'abord les données en blocs et affecte une valeur ou une clé de hachage unique à chaque bloc. Les valeurs de hachage sont envoyées au serveur de points de récupération. Le serveur de points de récupération compare ces valeurs de hachage avec les valeurs de hachage existantes et les hachages dupliqués sont éliminés. Les résultats de la comparaison sont alors renvoyés à l'agent. En fonction de ces informations de hachage dupliquées, l'agent envoie les blocs de données uniques sur le serveur de points de récupération pour leur sauvegarde. Les nouvelles valeurs de hachage de ces blocs de données sont également insérées dans la liste de hachages existante sur le serveur de points de récupération.
Lorsqu'il y a plusieurs agents, le processus de déduplication reste le même ; toutefois, les données dupliquées à partir de plusieurs agents sont éliminées. Cela permet d'éliminer toutes les duplications de données provenant de plusieurs agents.
Les avantages de la déduplication de données dans Arcserve UDP sont les suivants :
|
Copyright © 2015 Arcserve.
Tous droits réservés.
|
|