

Il processo di deduplicazione dei dati di Arcserve UDP consente di dividere i dati in blocchi, ciascuno dei quali viene assegnato a un identificatore univoco denominato hash. L'hash viene calcolato in base al cluster del volume. La dimensione dei blocchi di deduplicazione predefinita è 4KB (la dimensione dei cluster del volume predefinita è 4KB per la maggior parte dei nodi). Tali valori hash vengono confrontati con i valori hash dei dati di backup esistenti e qualora vengano rilevati riferimenti duplicati, non viene eseguito il backup di quei blocchi di dati. Viene eseguito il backup solamente dei blocchi di dati con riferimenti univoci.
Il diagramma seguente illustra il funzionamento della deduplicazione in Arcserve UDP.
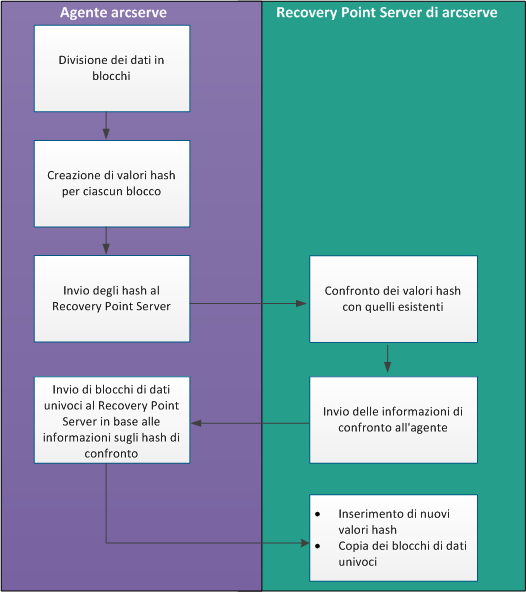
Quando un backup viene attivato, il processo di deduplicazione sull'agente suddivide prima i dati in blocchi e assegna una chiave hash univoca o un valore univoco a ciascun blocco. I valori hash vengono quindi inviati al Recovery Point Server. Nel Recovery Point Server, tali valori hash vengono comparati con i valori hash esistenti e gli hash duplicati vengono eliminati. I risultati della comparazione vengono rimandati all'agente. In base alle informazioni sugli hash duplicati, l'agente invia i blocchi di dati univoci al Recovery Point Server per il backup. I nuovi valori hash di questi blocchi di dati vengono inseriti nell'elenco degli hash esistenti sul Recovery Point Server.
Quando ci sono più agenti, il processo di deduplicazione rimane lo stesso, tuttavia, i dati duplicati dagli agenti vengono eliminati. Ciò consente di eliminare qualsiasi duplicazione di dati da vari agenti.
Di seguito vengono elencati i benefici derivanti dalla deduplicazione di dati in Arcserve UDP:
|
Copyright © 2015 Arcserve.
Tutti i diritti riservati.
|
|