

O processo de redução de redundância da Arcserve UDP divide os dados em blocos de dados e a cada bloco é atribuído um único identificador denominado hash. O hash é calculado com base no agrupamento de volume. O tamanho do bloco de redução de redundância padrão é de 4 KB (o tamanho do agrupamento do volume padrão é de 4 KB para a maioria dos nós). Esses valores de hash são comparados aos valores de hash dos dados de backup existentes e, se as referências de duplicação forem encontradas, não será feito backup desses blocos de dados. Apenas será feito o backup dos blocos de dados com referências exclusivas.
O diagrama a seguir ilustra como funciona a redução de redundância na Arcserve UDP.
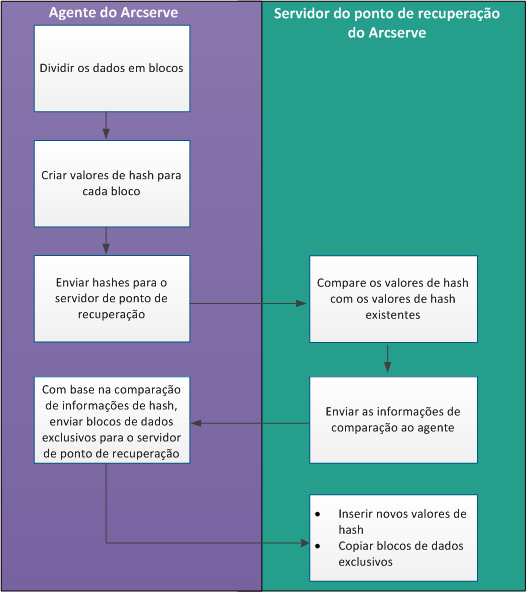
Quando um backup é acionado, o processo de redução de redundância no agente primeiro divide os dados em blocos e atribui uma chave de hash ou valor exclusivo para cada bloco. Em seguida, os valores de hash são enviados para o servidor de ponto de recuperação. No servidor de ponto de recuperação, esses valores de hash são comparados aos valores de hash existentes e os hashes duplicados são filtrados. Os resultados da comparação são enviados de volta para o agente. Com base nessas informações hash duplicadas, o agente envia os blocos de dados exclusivos para o servidor de ponto de recuperação para backup. Os novos valores de hash desses blocos de dados também são inseridos em sua lista de hash existente no servidor de ponto de recuperação.
Quando houver vários agentes, o processo de redução de redundância permanece o mesmo, no entanto, os dados duplicados de vários agentes são filtrados. Isso elimina qualquer duplicação de dados, mesmo que seja de vários agentes.
Abaixo estão os benefícios de usar a redução de redundância de dados na Arcserve UDP
|
Copyright © 2015 Arcserve.
Todos os direitos reservados.
|
|