

El proceso de deduplicación de Arcserve UDP divide los datos en bloques de datos y a cada bloque se le asigna un identificador único llamado hash. Hash se calcula basándose en el clúster de volúmenes. El tamaño del bloque de deduplicación predeterminado es de 4 kB (el tamaño del clúster de volúmenes predeterminado es de 4 kB para la mayor parte de los nodos). Estos valores de hash se comparan con los valores de hash de los datos de copia de seguridad existentes y si se encuentran referencias duplicadas, no se realizará la copia de seguridad de esos bloques de datos. Solamente se realiza la copia de seguridad de los bloques de datos con referencias únicas.
El diagrama siguiente ilustra cómo funciona la deduplicación en Arcserve UDP.
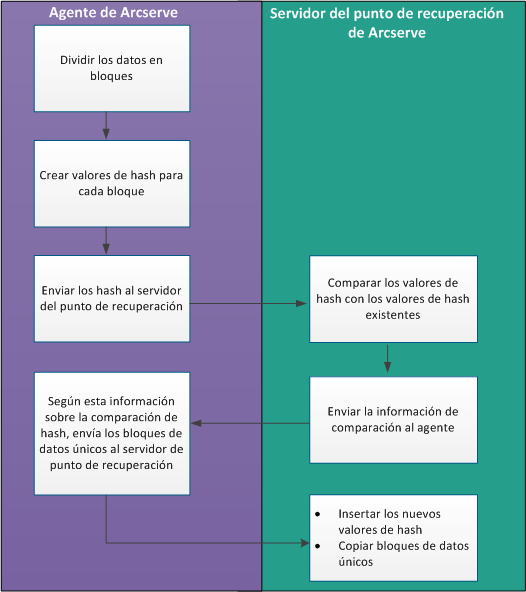
Cuando una copia de seguridad se activa, el proceso de deduplicación en el agente primero divide los datos en bloques y asigna una clave de hash o valor únicos a cada bloque. Los valores de hash se envían a continuación al servidor de punto de recuperación. En el servidor de punto de recuperación, estos valores de hash se comparan con los valores de hash existentes y se filtran los hash duplicados. Los resultados de la comparación se devuelven al agente. Según esta información de hash duplicada, el agente envía los bloques de datos únicos al servidor de punto de recuperación para realizar la copia de seguridad. Los valores de hash nuevos de estos bloques de datos también se insertan en la lista de hash existentes en el servidor de punto de recuperación.
Cuando hay varios agentes, el proceso de deduplicación permanece el mismo, pero los datos duplicados de varios agentes se filtran. Esto elimina cualquier duplicación de los datos incluso de varios agentes.
A continuación se muestran los beneficios de utilizar la deduplicación de datos en Arcserve UDP:
|
Copyright © 2016
|
|